A plain-English explanation of what happens when ChatGPT, Claude, Perplexity and Gemini answer a question about your business, and what it means for how you should be preparing.
A plain-English explanation of what happens when ChatGPT, Claude, Perplexity and Gemini answer a question about your business, and what it means for how you should be preparing.
By Mike Rogers, Co-founder of KnownEntity.ai
When someone asks ChatGPT "who are the leading glass packaging suppliers in the UK," what actually happens behind the scenes? Most people picture something like this. ChatGPT goes off, opens a few websites, has a quick read, and comes back with an answer.
That mental model feels intuitive. It is also wrong. And the gap between how people imagine AI assistants work and how they really work is the single biggest source of wasted effort in AI visibility planning today.
This piece walks through what is actually happening, in language you do not need a technical background to follow. If you are responsible for how your business shows up in AI answers, the picture below is worth ten minutes of your time.
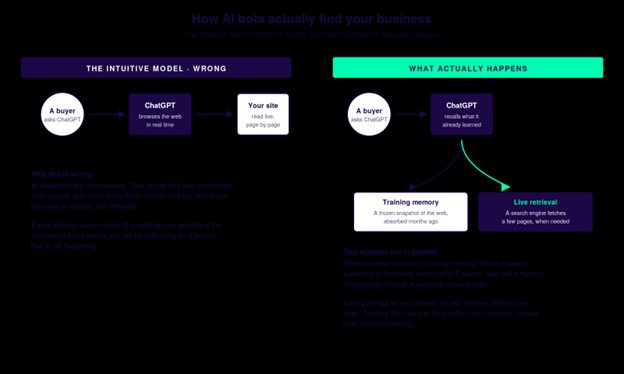
The picture in your head, and the picture that is real
The intuitive model has the AI behaving like a research assistant with a browser. Question comes in, AI goes off and reads the web, AI returns an answer.
What is actually happening is closer to two systems running in parallel.
The first system is the AI's training memory. Every model you have heard of, ChatGPT, Claude, Gemini, Copilot, was built by absorbing a massive snapshot of the public web during a training process that ended months before the model was released. When you ask Claude about UK glass packaging suppliers, most of what it tells you is recalled from that snapshot. It is not browsing your website at the moment of the question. It is remembering what was on your website, in the trade press, in directories, and on Wikipedia at the time the snapshot was taken.
The second system is live retrieval. Some AI products, particularly Perplexity and the search modes of ChatGPT and Claude, do go and fetch a small number of pages in real time. But even here, they are not browsing in the human sense. They issue a search query to a search index, take the top handful of results, read them, and synthesise an answer.
Two systems. Two timelines. Two sets of rules. Confuse them and you will optimise for the wrong thing.
There is no such thing as "the AI bot"
Here is the second misconception. People talk about "the AI bot" as if there is a single program crawling the web on behalf of all AI tools. There is not. Each major provider runs several separate crawlers, each with a specific job, and they can be controlled independently.
This is not a small detail. It is the difference between being cited by ChatGPT and being invisible in it.

OpenAI runs three. GPTBot crawls the web to gather material for training future versions of its models. OAI-SearchBot maintains the search index that ChatGPT reaches into when a user asks a question that needs current information. ChatGPT-User fetches a specific page when a user clicks on a citation or asks ChatGPT to read a particular URL.
Anthropic, the company behind Claude, formalised the same three-tier pattern in early 2026. ClaudeBot is the training crawler. Claude-SearchBot indexes for Claude's web search feature. Claude-User fetches in real time when a user invokes a page during a Claude session.
Perplexity is a slightly different shape. Because Perplexity is a retrieval-only product (it does not train its own foundation model from scratch), it runs two crawlers rather than three. PerplexityBot builds the search index that powers every Perplexity answer. Perplexity-User fetches pages in real time during a user session.
Google sits in its own category. Google-Extended is the user-agent you can allow or disallow to control whether your content is used in Gemini training and AI Overviews. The live grounding for AI Overviews and Gemini is handled by Google's wider crawler infrastructure, which has not been split out into the same clean three-bot pattern that OpenAI and Anthropic now use.
The implication of this is concrete and often missed. The old binary choice (allow AI bots, or block them) is gone. You now have a per-provider, per-job set of decisions to make. You can be in ChatGPT's search index without being in OpenAI's training data. You can be in Claude's training data without ever being cited in a real-time Claude answer. The decisions are not interchangeable.
For most established B2B businesses, the right answer is to allow all of these crawlers. Blocking the search bots is a direct trade-off with visibility today. Blocking the training bots is a longer-term decision about whether you want to be in the next generation of models. Blocking the user-fetch bots affects whether a user can ask Claude or ChatGPT to read your page on demand. None of these are the same conversation, and any sensible robots.txt now reflects that.
The two timelines that matter
The third thing worth understanding is that the work you do today shows up on two different clocks.
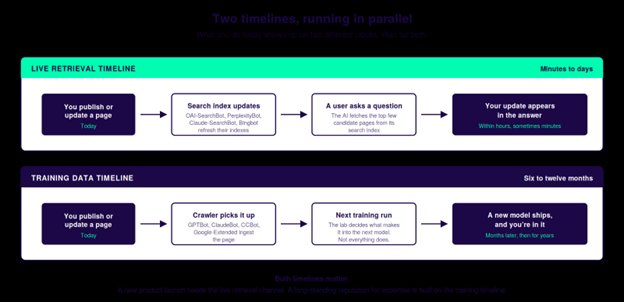
When you publish or update a page on your site, the live retrieval timeline kicks in quickly. The search-indexing crawlers (OAI-SearchBot, PerplexityBot, Claude-SearchBot, Bingbot) refresh their indexes on cycles that range from minutes to days, depending on the site and the page. The next time a user asks an AI assistant a question that triggers live retrieval, the updated content can appear in the answer almost immediately.
The training timeline is much slower. The training crawlers (GPTBot, ClaudeBot, CCBot, Google-Extended) ingest your page into a vast pool of candidate training data. From there, the AI lab decides what makes it into the next training run, and not everything does. When the next model ships, six to twelve months later, your update may be reflected in what the model knows. And because that knowledge then sits inside the model's weights, it shapes answers for years afterwards, even when no live retrieval happens at all.
Both timelines matter, and they suit different commercial purposes.
A new product launch needs the live retrieval channel. You cannot wait six months for a new offer to be reflected in AI answers. The fix is to make sure your owned site is structurally clean (so search crawlers can read it), that the new content is genuinely answer-shaped, and that it is linked from authoritative external sources that the search indexes already trust.
A long-standing reputation for expertise is built on the training timeline. When somebody asks Claude "who is a credible voice on water hygiene compliance in the UK," the answer is shaped by what was in the training corpus six to twelve months ago. That cannot be fixed in a week. It is the result of a sustained pattern of being mentioned, cited, and described accurately across the open web, over time.
The two timelines are not in tension. They are complementary. But you have to plan for both, with different tactics for each.
What this means in practice
Three things follow from all of this, and they are worth being explicit about.
First, your own website is not the whole game. A McKinsey analysis from August 2025 found that a brand's own website contributes only around 5–10% of the sources AI platforms draw on when answering a question. The other 90% is earned: trade press, directories, Wikipedia, Wikidata, professional associations, expert commentary, citations from other people's content. If you are pouring resources into making your own site AI-friendly without touching the external footprint, you are working on a small slice of the problem.
Second, robots.txt is now a strategic document, not a technical one. A surprising number of sites accidentally block AI crawlers because they are using stock robots.txt templates from 2021 that disallow anything matching the pattern "bot." A quarterly check of which AI crawlers can actually reach your site, and which cannot, is now basic hygiene. The cost of getting it wrong is invisibility.
Third, the answer to "what should AI say about us" starts upstream of any tool or technique. Before you optimise anything, you need to be clear about what your business genuinely wants to be cited for, by whom, in what commercial context. Appearing in AI answers for the wrong things is almost as damaging as not appearing at all. If your AI footprint over-indexes on a small slice of what you actually do, the fix is not more crawler-friendly content. It is a strategic conversation about which parts of the business should be visible, and a deliberate plan to shape that.
That third point is the one that matters most for established, non-digital-native businesses with deep expertise and a thin or skewed AI presence. The technical layer is real and it has to be right, but it is the easy part. The harder, and more valuable, work is upstream of the technology.
Mike Rogers is co-founder of KnownEntity.ai, a UK-based consultancy that helps established B2B businesses become properly known by AI systems. The AI Authority Ladder™ methodology runs from diagnostic audit through EntityCore™ build, citation strategy, and measurement. If you would like to know how your business currently appears across ChatGPT, Claude, Perplexity, and Gemini, the Diagnostic is a good place to start.
knownentity.ai · hello@knownentity.ai
Last updated: 28 April 2026
Find out where you stand
An AI Visibility Audit gives you a clear, actionable picture of your current AI Authority and how you compare to your competitors.
Request Your Audit